 Planificación y Optimización Paralela de Redes Logísticas de Transporte
Planificación y Optimización Paralela de Redes Logísticas de Transporte
Aplicación
Introducción
En este capítulo vamos a pasar a describir en detalle que consiste y como funciona la aplicación, utilizando los conceptos definidos en el capítulo anterior. Empezaremos definiendo como se modela el sistema con un ejemplo de pequeño tamaño y que utilizaremos a lo largo del capítulo como caso de estudio para ver como se resolvería un problema real.
Más adelante veremos que método se ha utilizado para aislar al usuario de la programación por restricciones y de CPLEX, de tal forma que los conocimientos sobre las redes logísticas de gas sean lo único necesario para poder utilizar la aplicación de una forma totalmente funcional.
Por último se explicará como explotar el paralelismo inherente a los análisis de sensibilidad utilizando servicios web y computación distribuida., englobándolo en el uso de la aplicación.
Modelado de la Red
Como se explicó en el apartado dedicado a CPLEX, un problema consta de dos ficheros: uno que contiene el modelo propiamente dicho y otro que incluye los datos a ejecutar con ese modelo. Vamos a introducir un sistema sencillo y veamos como se modela:
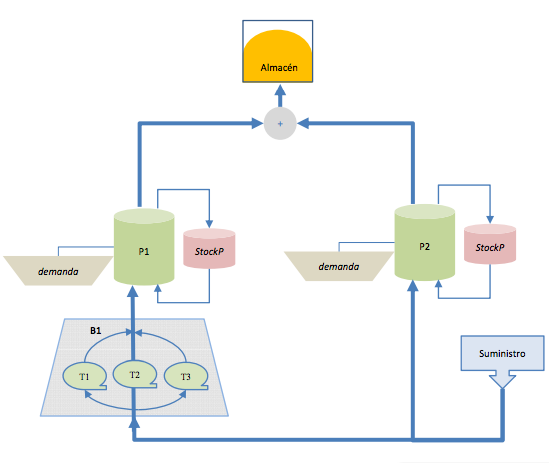
Como se puede ver, este es un sistema que tiene un único punto de suministro pero con dos salidas, una va directamente a una estación de compresión y otra a un almacén a través de una tubería. Por el otro extremo de la bomba sale a su vez otra tubería que se conecta a la anterior y al almacén, cerrando el circuito. Cada tubería tiene un punto de demanda que hay que satisfacer para que el sistema tenga solución. Desglosemos el fichero que modelaría este sistema.
Primero, hay que definir los parámetros que afectan a todo el sistema: El número de ciclos de ejecución y dos rangos que se usarán como tamaño de las matrices de datos. Los puntos suspensivos en una variable indican que no está definida y que por tanto debe introducirse un valor en el fichero de datos.
//DATOS
int Periodo= ...; //Numero de ciclos
range T = 1.. Periodo ; //Rango sin condiciones iniciales
range T0 = 0.. Periodo ; //Rango con condiciones iniciales
A continuación, para cada clase de elemento del sistema hay que definir los datos que va a utilizar y que son los que definirá el usuario:
//Modelo de la estación de compresión (Bidireccional) Datos
int numTurbos = ...; //Posiciones de funcionamiento de las bombas;
{string} bombas = ...; //Nombres de las estaciones;
range turbos = 1..numTurbos; //Rango de posiciones de funcionamiento;
float fMin[bombas,turbos] =...;
//Flujo mínimo en función de la posición y la estación;
float fMax[bombas,turbos] =...;
//Flujo máximo en función de la posición y la estación;
float consumo[bombas,turbos] = ...;
//Consumo en función de la posición y la estación;
//Modelo de almacenamiento (Bidireccional) Datos
{string} almacenes = ...; //Nombres de los almacenes
int cuota [almacenes]= ...; //Capacidad de entrada/salida
float stockInitA[almacenes]= ...; //Estado inicial
//Modelo de conducción (Bidireccional) Datos
{string} pipes = ...; //Nombres de las tuberías
float stockInitP[pipes]= ...;//Estado inicial de las tuberías
float stockMinP[pipes]= ...; //Capacidad mínima de las tuberías
float stockMaxP[pipes]= ...; //Capacidad máxima de las tuberías
float demandaP[T,pipes]= ...;//Demanda de salida por tubería e instante
//Modelo de suministro (Planta) Datos
{string} plantas = ...; //Nombre de las plantas
float suministro[T,plantas] = ...;//Producción de la planta por periodo
Una vez hecho esto, hay que definir las variables que se pretende optimizar. Estas serían las variables que se dejan "libres" y las que CPLEX manipula para alcanzar el óptimo. Igual que en el apartado anterior, cada clase de elemento tiene unas variables:
//Modelo de la estación de compresión (Bidireccional) Variables
dvar int dp[T,bombas,turbos] in 0..1; //Flujo positivo?
dvar int dn[T,bombas,turbos] in 0..1; //Flujo negativo?
dvar float FlujoBP[T,bombas]; //Flujo en dirección positiva
dvar float FlujoBN[T,bombas]; //Flujo en dirección negativa
dvar float+ FlujoB[T,bombas]; //Flujo total en la bomba
//Modelo de almacenamiento (Bidireccional) Variables
dvar float FlujoA[T,almacenes]; //Flujo que entra/sale del almacén
dvar float+ StockA[T0,almacenes]; //Cantidad que queda en el almacén
//Modelo de conducción (Bidireccional) Variables
dvar float FlujoPE[T,pipes]; //Flujo de entrada de la tubería
dvar float FlujoPS[T,pipes]; //Flujo de salida de la tubería
dvar float StockP[T0,pipes]; //Cantidad que hay en la tubería
//Modelo de suministro (Planta) Variables
dvar float+ suministroP[T,plantas];
La función objetivo del problema se coloca a continuación
//Función objetivo (Minimizar el consumo de las estaciones de compr.)
minimize sum(i in T,j in bombas, k in turbos)
(dp[i,j,k]+dn[i,j,k])*consumo[j,k];
Definidas todas las variables que intervienen en el problema, toca el turno para las restricciones que las relacionan entre sí. Una vez más, se agrupan por tipo de elemento. Nótese que todas estas restricciones deben ir encapsuladas en un bloque "subject to {...}"
subject to
{
//Modelo de la estación de compresión (Bidireccional) Restricciones
forall(t in T, j in bombas)
{
sum(k in turbos)dp[t,j,k]*fMin[j,k] <= FlujoBP[t,j];
//El flujo positivo es mayor que el minimo de funcionamiento de la bomba
sum(k in turbos)dp[t,j,k]*fMax[j,k] >= FlujoBP[t,j];
//El flujo positivo es menor que el maximo de funcionamiento de la bomba
sum(k in turbos)dn[t,j,k]*(-fMin[j,k]) >= FlujoBN[t,j];
//El flujo negativo es mayor que el minimo de funcionamiento de la bomba
sum(k in turbos)dn[t,j,k]*(-fMax[j,k]) <= FlujoBN[t,j];
//El flujo negativo es menor que el maximo de funcionamiento de la bomba
sum(k in turbos)(dp[t,j,k]+dn[t,j,k])==1;
//Solo se puede bombear en un sentido en un momento dado
FlujoB[t,j] == FlujoBP[t,j]+FlujoBN[t,j];
//El flujo total es la suma del flujo positivo y del negativo
}
Se puede obsevar que estas restricciones se pueden representar de forma púramente matemática. Por ejemplo, la primera de las restricciones anteriores es equivalente a:

forall(j in almacenes)
StockA[0,j] == stockInitA[j]; //Estado inicial de los almacenes
forall(t in T, j in almacenes)
{
StockA[t,j]==StockA[t-1,j] + FlujoA[t,j];
//El estado del almacén en el momento t es el del momento
t-1 + el flujo de entrada/salida
-cuota[j] <=FlujoA[t,j]<= cuota[j]
//El flujo de entrada/salida esta dentro del rango permitido
}
//Modelo de conducción (Bidireccional) Restricciones
forall(i in pipes)
StockP[0,i] == stockInitP[i]; //Estado inicial de las tuberías
forall(t in T, j in pipes)
{
FlujoPS[t,j]== FlujoPE[t,j]+StockP[t-1,j]-StockP[t,j]-demandaP[t,j];
//El flujo de salida en el instante t es el flujo de entrada en ese
//instante, más la cantidad de de gas que había en la tubería en el
//instante t-1, menos la cantidad de gas que queda en la tubería,
//menos la demanda que ha salido de la tubería al exterior
StockP[t,j] <= stockMaxP[j];
//La cantidad de gas que transporta la tubería no excede sus limites
//estructurales
StockP[t,j] >= stockMinP[j];
//La cantidad de gas que transporta la tubería está por encima del
//mínimo de funcionamiento
}
Finalmente hay que añadir las restricciones que definen realmente el modelo. Todo lo anterior solo afecta a la forma en la que se definen los distintos componentes del modelo y, llegado el caso podrían utilizarse tal cual aparecen para cualquier modelo en el que no se quisiesen introducir más parámetros. (Por ejemplo, si se decidiese que para una orografía particular el factor de inclinación de las tuberías es importante y debiera tenerse en cuenta, habría que modificar el modelo de la tubería y sus restricciones de forma adecuada) En cualquier caso, la topografía concreta de un modelo se define en esta parte como un conjunto de restricciones del flujo. Estas fuerzan que en todos los nodos de la red el flujo combinado sea igual a cero o lo que es lo mismo, que el gas no se fuga del sistema ni se inyecta más allá del punto de suministro. Para el modelo que aparece al comienzo de esta sección estas restricciones serían:
forall(t in T)
{
FlujoPE[t,"P1"]== FlujoB[t, "B1"];
FlujoPS[t,"P1"]+FlujoPS[t,"P2"]== FlujoA[t,j];
FlujoB[t,"B1"]+FlujoPE[t,"P2"]== suministro[t,"PL1"];
}
}//Fin de las restricciones
}//Fin del programa
La primera de ellas indica que el flujo de entrada en la tubería uno es el flujo de salida de la estación de compresión, la segunda que el flujo de salida de la tubería uno más el flujo de salida de la tubería dos es la cantidad de gas que entra en el almacén y la tercera que el flujo de entrada en la bomba más el flujo de entrada en la tubería dos debe ser igual a la cantidad que entra en el sistema.
Con esto queda definido un modelo que deberá estar alojado en cada uno de los servidores para realizar el cálculo. Comentemos ahora como queda definido el fichero de datos que permite ejecutarlo. Este es sustancialmente más corto y sencillo que el modelo, como se puede ver a continuación:
//DATOS
Periodo = 3; //Numero de ciclos
//----------------------------------------------------------------------
//Modelo de la estación de compresión (Bidireccional) Datos
numTurbos=3; //Posiciones de funcionamiento de las bombas;
bombas = {"B1"}; //Nombres de las estaciones;
fMin = [[10.1, 20.2,30.3]];
//Flujo mínimo en función de la posición y la estación;
fMax = [[15.1, 25.2,35.3]];
//Flujo máximo en función de la posición y la estación;
consumo = [[15.1, 25.2,35.3]];
//Consumo en función de la posición y la estación;
//----------------------------------------------------------------------
//Modelo de almacenamiento (Bidireccional) Datos
almacenes = {"A1"}; //Nombres de los almacenes
cuota= [40]; //Capacidad de entrada/salida
stockInitA= [0]; //Estado inicial
//----------------------------------------------------------------------
//Modelo de conducción (Bidireccional) Datos
pipes = {"P1","P2"};//Nombres de las tuberías
stockInitP= [0,0]; //Estado inicial de las tuberías
stockMinP= [0,0]; //Capacidad mínima de las tuberías
stockMaxP= [10,10]; //Capacidad máxima de las tuberías
demandaP= [[40,30],[30,15],[10,20]];
//Demanda de salida en cada tubería e instante
//----------------------------------------------------------------------
//Modelo de suministro (Planta) Datos
plantas = {"PL1"}; //Nombre de la planta
suministro = [[120],[180],[90]]; //Producción por periodo
Como se puede ver, se trata de rellenar los valores que se dejaron sin rellenar en el modelo,prestando atención a utilizar los mismos nombres para las variables y los mismos tipos de datos ya definidos.
Creación del Fichero de Datos
Aunque el fichero con el modelo sin duda tiene que ser creado por alguien que conozca como funciona la red y que tenga conocimientos de OPL y CPLEX, no ocurre lo mismo con el fichero de datos. Cualquier personas que pueda tener acceso a la distribución de la red de gas debería poder utilizar la aplicación sin conocimientos previos de ningún lenguaje de programación. Por tanto se ha añadido una capa intermedia de comunicación con el usuario que permite leer los datos directamente de un fichero de Microsoft Excel. Se ha escogido este formato por su facilidad de uso y su amplia extensión. Aunque se proporciona una plantilla con la aplicación, debido a que el usuario debe conocer el modelo, él mismo puede crear uno de estos ficheros y rellenarlo con los datos que desee. A continuación se muestra uno de estos ficheros y que representa cada una de sus partes:
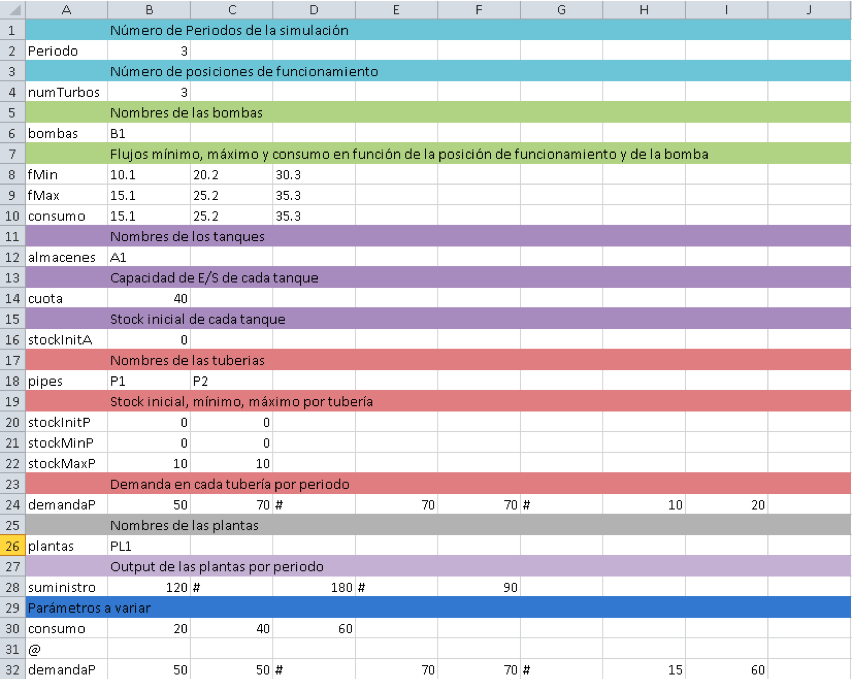
Las filas coloreadas son meramente informativas pero deben colocarse antes de cada dato para que el archivo sea correctamente procesado. La columna de la izquierda contiene los nombres de los distintos elementos del modelo. Por ejemplo, en este modelo la matriz que contiene la demanda por tubería y periodo se llama "demandaP". A su vez, las matrices se definen mediante secuencias de vectores en los cuales cada línea va separada de la siguiente por una almohadilla (#). Las celdas en blanco no cuentan a la hora de procesar el fichero. Esto facilita la lectura ya que, si por ejemplo este modelo tuviese una segunda estación de compresión, sus valores de flujos mínimo, máximo y consumo se escribirían en la fila adecuada a partir de la columna cinco. Podríamos dejar las columnas dos, tres y cuatro de la fila nombre en blanco y escribir el nombre de la estación 2 en la cinco de tal forma que quedase alineada con sus datos.
Sin embargo la parte más importante del fichero es la sección de "Parámetros a variar". Entre el título y la marca de fin de fichero se pueden repetir los nombres de las partes del modelo y un valor alternativo de los datos que se ejecutarán en un servidor diferente. Cada una de estas alternativas se debe separar mediante una línea con la marca "@". Esto se explicará con detalle en la sección "Paralelismo" de este capítulo. Por ahora baste decir que por cada valor extra que se introduzca en esta parte del fichero, se ejecuta una instancia del problema con todos los datos iniciales excepto el marcado que es el que varía. Por ejemplo, para la imagen que aparece más arriba, se ejecutaría el modelo en un servidor con todos los parámetros que aparecen, incluyendo un flujo mínimo de las estaciones de 10.1 unidades en la posición de la bomba 1, 20,2 en la posición 2 y 30,3 en la posición 3. A su vez, en otro servidor se ejecutaría este mismo modelo con los mismos parámetros, a excepción del flujo mínimo que valdría 20, 23 y 56 respectivamente para cada una de las citadas posiciones.
Utilizando este formato, no solo se facilita una mayor accesibilidad a la aplicación sino también se limitan los potenciales errores que se pueden cometer al fichero de datos. Se debe resaltar que el modelo que hemos mostrado no es más que un pequeño ejemplo, un modelo real podría tener varias plantas de suministro, docenas de estaciones de compresión y almacenes y centenares de tuberías. Esto implicaría un fichero de datos que podría tener varios cientos de líneas de código. Si suponemos que el usuario de la aplicación no dispone del entorno de desarrollo gráfico de CPLEX (Como sería lo normal, si no podría realizar los análisis localmente sin necesidad de recurrir a la red) la depuración de posibles errores de escritura se convierte en una tarea farragosa. Por el contrario, introducir únicamente valores numéricos en la hoja excel resulta mucho más sencillo y visualmente mucho más fácil de comprobar si se detecta que algo no funciona como debería.
Como la hoja de cálculo que crea el fichero .dat está íntimamente ligada al fichero con el modelo, las dos se almacenan juntas en las máquinas que posean CPLEX. Si un usuario desea hacer un análisis de sensibilidad, puede realizar una petición a una de estas máquinas, obteniendo como resultado la plantilla adecuada para el modelo totalmente vacía. Una vez más, esto permite que casi cualquier usuario pueda utilizar la aplicación sin ningún conocimiento previo a parte de saber como está estructurado el modelo. En un principio se pensó en enviar el modelo junto con el fichero excel con los datos al servidor en forma de paquete. Sin embargo, se desechó está idea debido a temas de licencias del resolutor (Veáse Anexo: Licencias).
Paralelismo
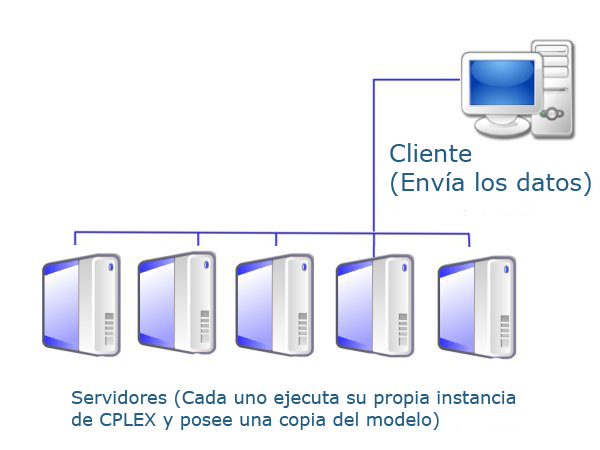
El usuario ya tiene listo su fichero con los datos a ejecutar. Es más, ya ha añadido las filas extra que incluyen los parámetros de su análisis de sensibilidad. El siguiente paso es enviar dicho fichero a una máquina que disponga de CPLEX y que pueda resolver el problema empleando el mínimo tiempo posible. Debido a la granularidad completa del mismo. (Ver capítulo 1: Paralelismo) lo ideal es hacer uso de tantas máquinas como valores del parámetro tengamos y ejecutar cada una de estas instancias en una máquina (a partir de ahora, servidor) diferente. El fichero debe guardarse en formato .xml (Cosa que permite Microsoft Excel) de tal forma que sea más sencilla su decodificación.
Para que esto pueda realizarse, los servidores deben estar conectados a la red y esperando peticiones. Por tanto, cada servidor estará ejecutando una instancia del servicio web de la aplicación. Este, junto con la aplicación de escritorio que dispone el cliente, es una de las dos partes que componen la misma y es, sin duda, la más importante. El cliente debe sin embargo saber en que dirección puede localizar a los servidores para enviar los datos. Antes de realizar ningún otro cálculo, se leen desde un fichero de configuración las direcciones de los servidores. A continuación se ejecuta un pequeño programa de prueba para comprobar que efectivamente se dispone de estos servidores. En caso de fallar esta fase, se notificaría al usuario para que redujese el número de valores del análisis de sensibilidad. La segunda motivación de este programa de prueba es obtener el tiempo que tarda en ejecutarse para así priorizar unas máquinas sobre otras. Una máquina excepcionalmente lenta o que ya esté soportando una carga de trabajo muy alta degradará en exceso el rendimiento de todo el análisis de sensibilidad. Por tanto se distribuye la carga de trabajo adecuadamente entre los servidores dependiendo de su velocidad.
Por tanto, la aplicación se estructura como un clúster, en el que el cliente es la máquina que utilizará el usuario y que está conectado con una serie de servidores en los que se han desplegado distintas instancias del servicio web. El cliente dispondrá de una lista de direcciones en las que conoce que se encuentran estos servidores y realizará una llamada a cada uno de los mismos para que ejecuten remotamente el procedimiento que resuelve el modelo. Para poder realizar esta tarea paralelamente, se crean tantos threads en la máquina cliente como servidores existan y se hace cada llamada en uno de los threads. La finalidad de esto último es que el cliente no tenga que esperar la respuesta de cada servidor para poder lanzar la petición al siguiente, si no que se realicen a la vez.
La diferencia que existen entre los mensajes que se envían a cada servidor radica en que estos mensajes implicarán que en cada servidor se ejecute el modelo para un valor diferente del parámetro seleccionado. Por tanto, los servidor ejecutarán el mismo modelo pero con distintos datos paralelamente e idealmente el análisis de sensibilidad se realizará en 1/n del tiempo que se tardaría en hacerlo secuencialmente. Este escenario ideal solo se presentará si todos los servidores son capaces de resolver el modelo con la misma rapidez y si el envío de mensajes entre estos y el cliente tarda siempre el mismo tiempo, pero en cualquier caso se consigue un grado de paralelismo total. Esto es debido como ya se ha explicado a que la granularidad del problema es absoluta: cada servidor no necesita realizar ninguna comunicación con otro servidor ni con el cliente una vez ha empezado el proceso de resolución que no sea devolver los resultados obtenidos.
El fichero de datos está en formato Excel como se ha dicho. Sin embargo, la conversión a .xml es inmediata, quedando estructuradas las celdas como un árbol de etiquetas. Esta es la segunda razón por la que se utilizó el formato Excel. Ya que el servicio web utiliza el SOAP como protocolo de mensajería, además de añadir el envoltorio y la cabecera necesarias, debe hacer una transformación de los datos del mensaje a formato .xml para poder enviarlos. Si los datos ya se encuentran efectivamente en ese formato, toda la tarea se realiza más rápidamente. Especialmente si se da el caso, como sería lo usual en si la aplicación estuviese desplegada en una empresa, de que el fichero de datos incluye cientos de parámetros para el sistema.
Otra idea importante a destacar es que en el momento que se hacen las peticiones en distintos threads, a cada uno de estos se le asigna un número secuencial. Este número se envía en la petición a cada servidor e identifica unívocamente a cada uno de ellos. La importancia de esto radica en que la tabla de datos se envía completa, esto es con toda la información de paralelismo íntegra en formato .xml y es en cada servidor donde se construye efectivamente el fichero de datos que usará el resolutor. Por tanto es necesario que durante este proceso de construcción se conozca cual de las filas que redefinen parámetros ha de usarse.
Una vez que se tienen los datos con la línea correcta que se debe utilizar en el servidor, se reconstruye un fichero de texto plano, que es el que CPLEX necesita para operar. Este fichero se guarda en la carpeta de almacenamiento temporal del servicio web y tiene una apariencia similar al que se muestra en la página 39 de esta memoria. Desde aquí, el procedimiento remoto realiza una llamada a la biblioteca ILOG del CPLEX que incluye tanto el fichero del modelo como el recién creado fichero de datos y se inicia el procedimiento de resolución con los algoritmos citados en el capítulo anterior.
CPLEX se utiliza en la aplicación escrita en C# por medio de las bibliotecas CPLEX e ILOG, que quedan de esta forma incluidas en el proyecto. Estas ofrecen toda una serie de funcionalidad que puede ser aprovechada para analizar la ejecución del modelo. A la hora de devolver los resultados, se añaden al fichero de datos una serie de líneas que permiten escribir los valores de las variables del sistema en su punto óptimo directamente en la hoja de cálculo que ha recibido el servidor. Recordemos que el principal interés a la hora de planificar es tanto conocer cual es dicho óptimo como saber que pasos hay que llevar a cabo para conseguirlo. En un sistema logístico de gas esto se traduce en a que régimen debemos poner a trabajar una estación de compresión en cada instante. Además nos interesan también otra serie de variables que nos proporcionan información sobre la cantidad de gas que circula por las tuberías, el estado de los almacenes en cada instante, etc.
Como hemos dicho estos valores necesarios para la planificación se escriben en la hoja de cálculo mediante sentencias en el fichero .dat. Estas son del estilo:
SheetConnection sheet("C:/TransientStorage/libro1.xml");
FlujoPE to SheetWrite(sheet,"RESULTADOS!D20:E22");
donde la primera sentencia crea la conexión entre CPLEX y el fichero Excel y la segunda es un ejemplo en el que se ordena que la variable "FlujoPE" que contiene el flujo de entrada en las tuberías en cada instante se escriba como una matriz en las celdas D20 a la E22 (Matriz de 2x3) en el libro resultados.
El servidor tras resolver el modelo y escribir los datos, devuelve de nuevo el fichero Excel, marcado de tal forma que se sepa en que servidor y con que datos concretos se realizó el cálculo. De esta forma el usuario final de la aplicación tiene de un vistazo no solo que solución es mejor, si no también como se comporta el sistema internamente para cada una de ellas.
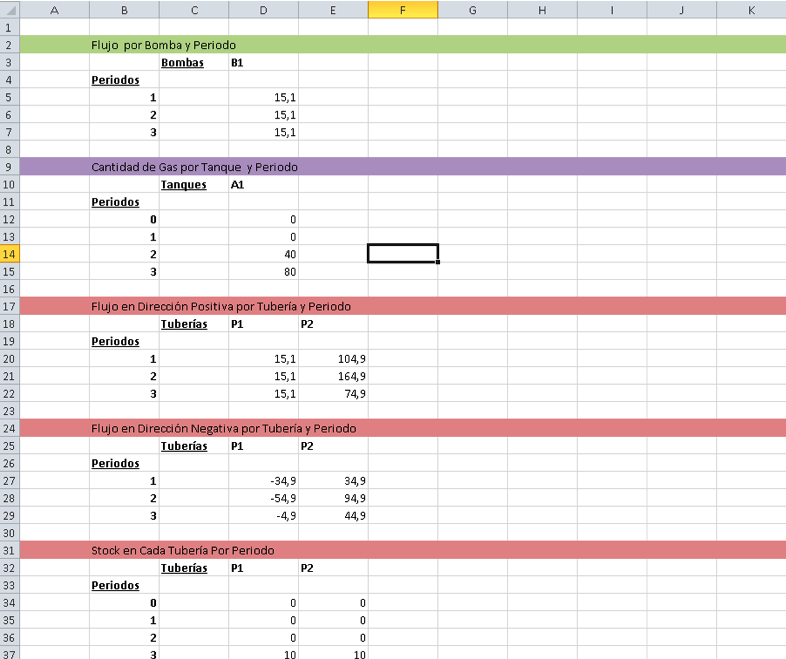
Con estos datos el usuario puede realizar la planificación del sistema. Por ejemplo, y para el sistema de prueba con el que hemos estado trabajando, habría que colocar la única estación de compresión del sistema en la posición de funcionamiento uno (La que mueve una cantidad de gas de 15.1 unidades por periodo) durante los tres periodos, obteniéndose un consumo de 45.3 unidades durante todo el periodo de planificación. La demanda quedaría plenamente satisfecha. El valor óptimo y la instancia concreta de los datos con los que se ejecutó el modelo pueden consultarse también como se ve en la siguiente imagen.
